What this proves
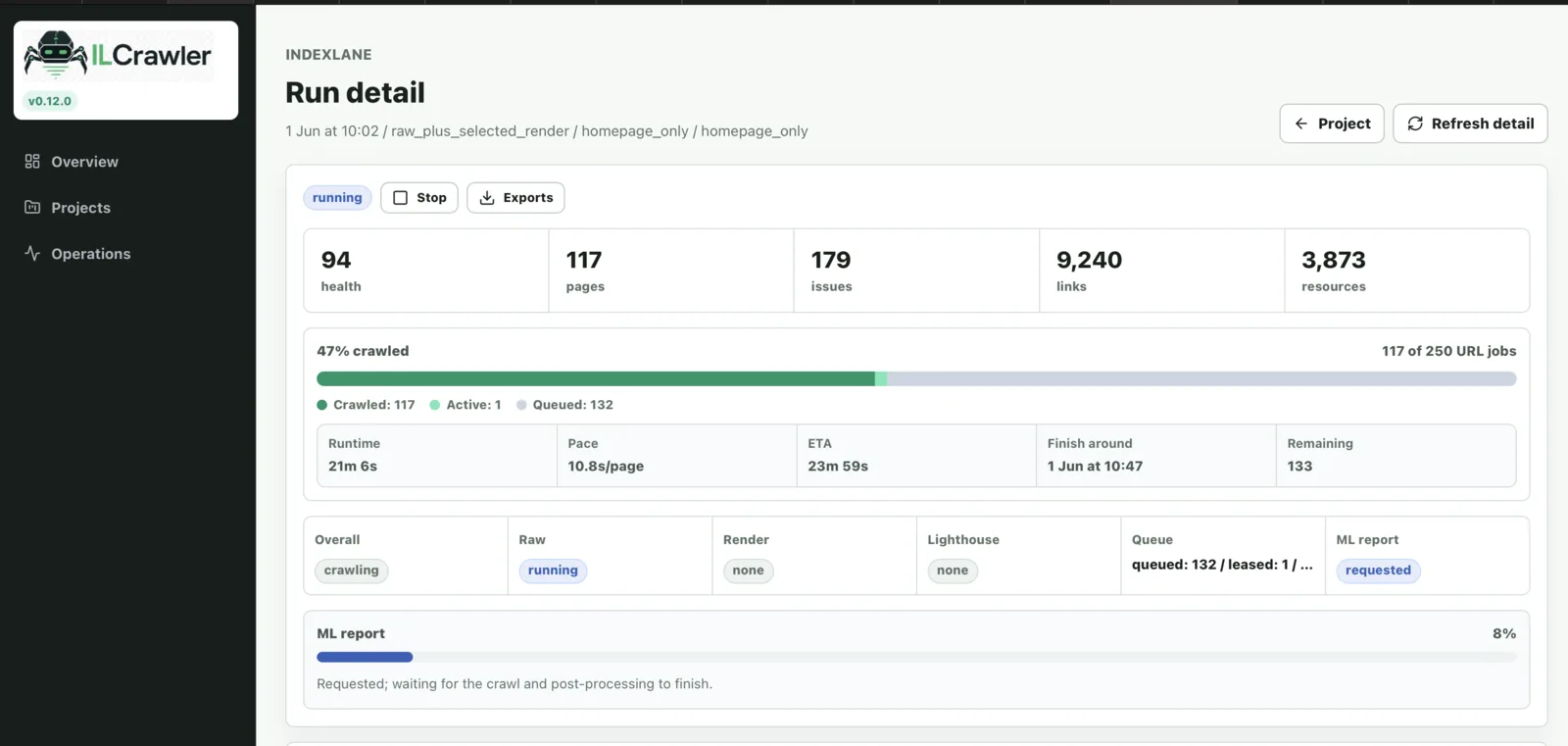
System behavior and guardrails
- Go raw crawling with bounded concurrency and batch spooling
- Rust idempotent importer for large raw evidence sets
- Browser rendering and local Lighthouse workers
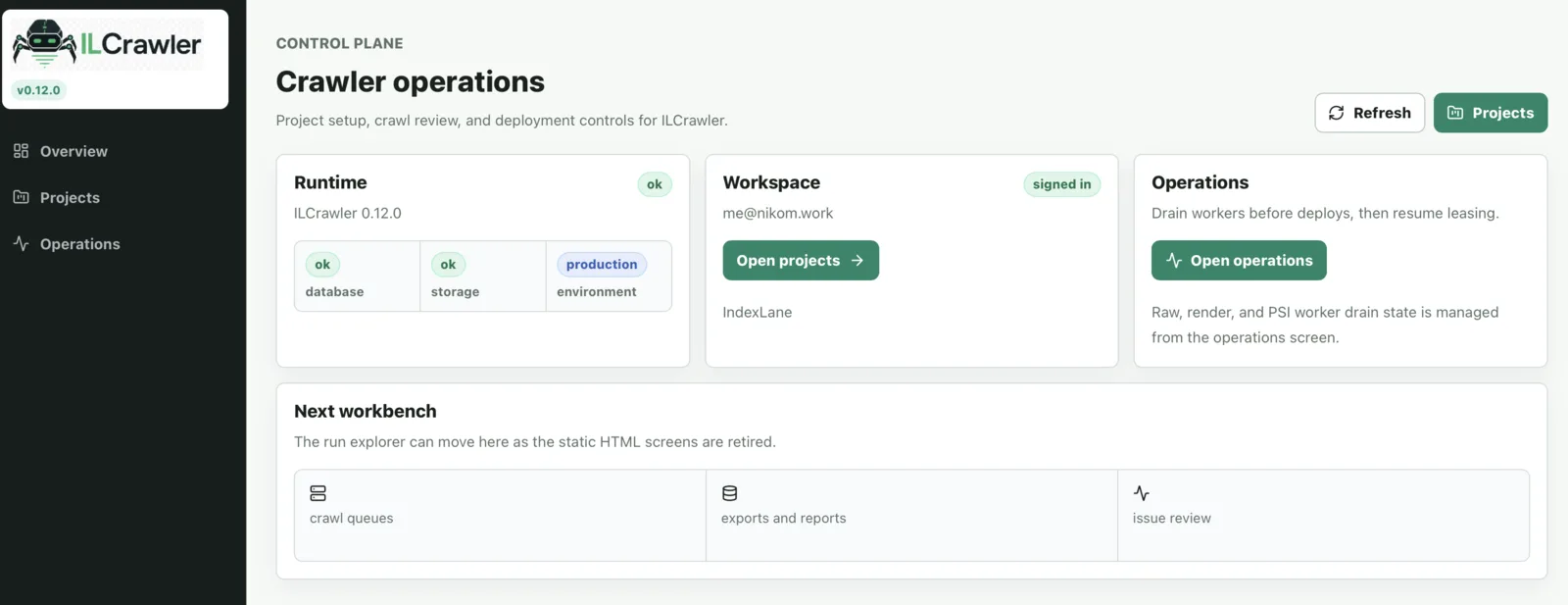
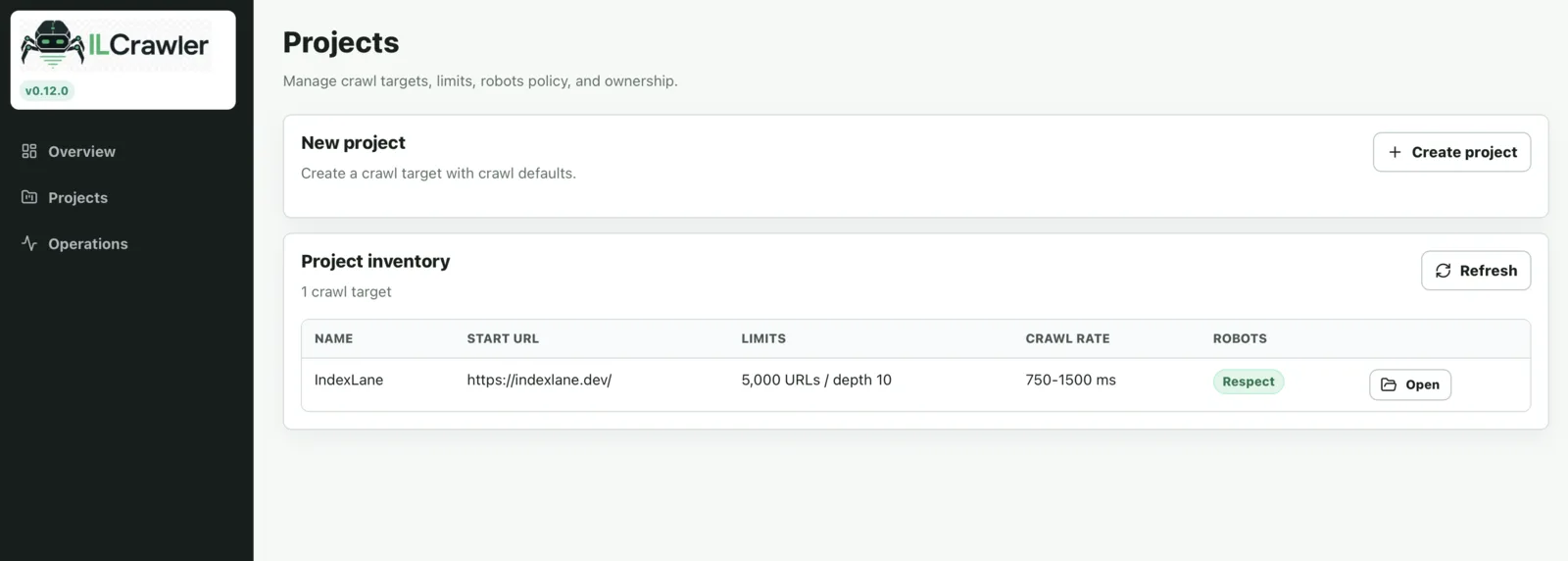
- Operator UI for projects, runs, issues, exports, and health